A Survey on Federated Learning for Resource-Constrained IoT Devices
리소스가 제한된 IoT 장치를 위한 연합 학습에 관한 서베이
이 글은 동명의 서베이 논문에서 내가 집중한 내용들을 추리고, 인용된 논문들에서 참고가 되는 내용들을 덧붙이고, 나의 의견을 함께 서술하였다.
Federated Learning (FL) Overview
Federated Learning (FL)은 여러 장치에서의 데이터를 중앙집중식으로 수집하지 않고, 각 장치에서 로컬로 학습된 모델을 중앙으로 집계함으로써 효율성과 보안을 보장하는 기술이다.
수십억 개의 연결된 IoT 장치로 인해 엣지 장치에서 수집 또는 생성되는 데이터는 계속 증가하고 있다. 전통적인 ML 방식은 데이터 센터나 기계에서 추출된 데이터 요소를 집계한다. 이러한 중앙 집중식 접근법은 개인정보 침해를 야기할 수 있다.
FL은 클라이언트의 개인 데이터를 다른 엔터티와 공유하지 않고 모델을 훈련시킬 수 있는 방식이다. 이는 사용자의 개인정보 보호 측면에서 강점을 가진다.
이 서베이는 FL 분야의 현재 챌린지들을 조사하고, 실제 제약 조건을 고려해서 그 영향에 대해 설명한다. 그리고 이 영역에서 아직 해결되지 않은 연구 이슈와 미래 방향을 논의한다.
Definition
FL은 분산 ML 접근법으로 정의할 수 있다. 이 접근법에서 클라이언트는 서버에 직접적인 정보를 공유하지 않으면서 로컬에서 훈련한다. 여기서의 핵심 개념은, 각 클라이언트의 모델 정보를 집계하여 공유된 글로벌 모델을 주기적으로 업데이트하는 것이다. 이를 통해 각 장치가 글로벌 뷰라고 하는 전체 네트워크의 데이터 패턴을 포착하게 된다.
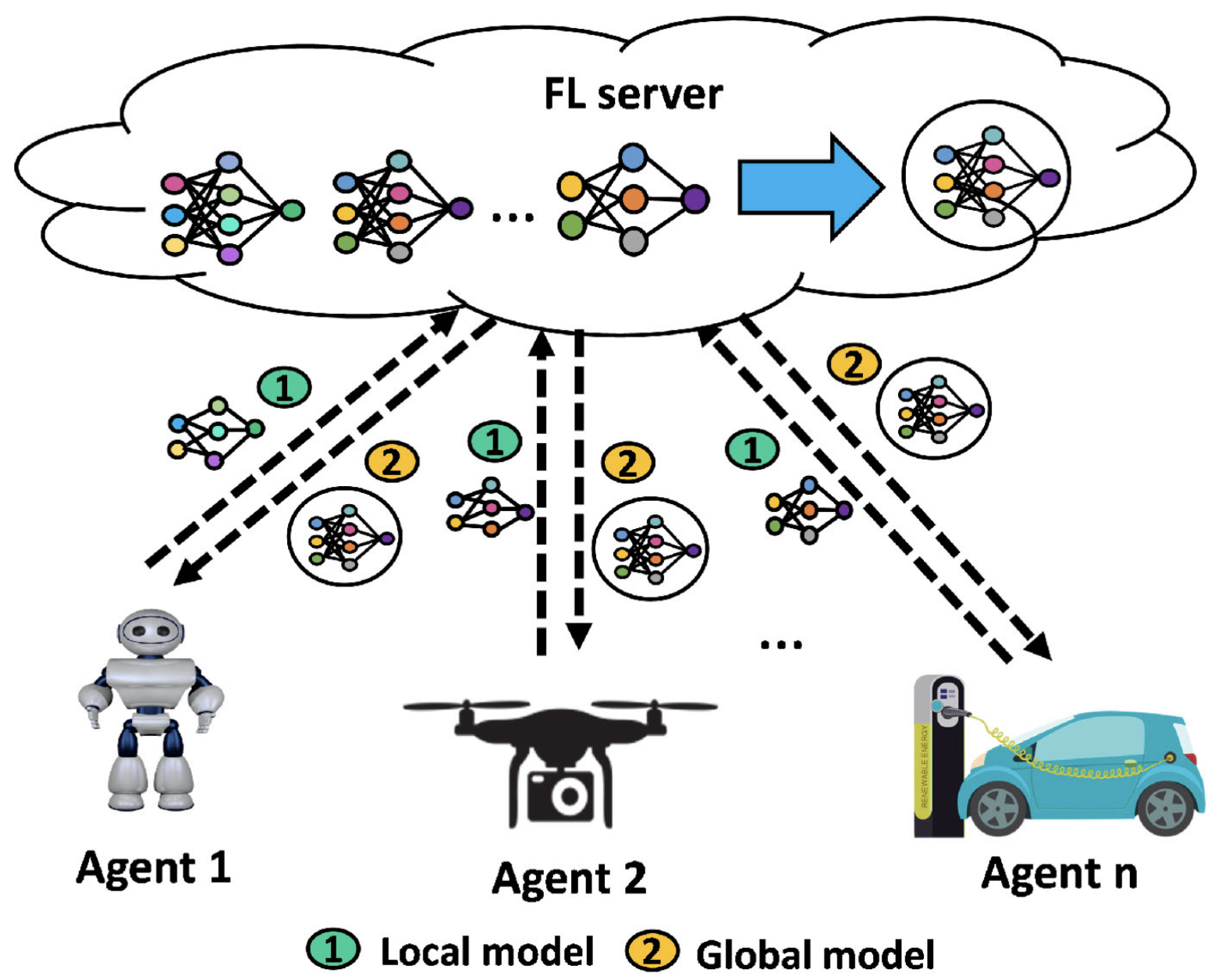 FL procedure considering N number of participants
FL procedure considering N number of participants
Process
FL은 크게 세 단계로 구성된다.
- Training Task & Global Model Initialization
- 중앙 서버가 작업 요구사항 및 대상 응용 프로그램 결정
- 글로벌 모델 초기화 및 참가자들에게 브로드캐스트
- Local Model Update
- 각 참가자는 로컬 데이터를 활용하여 모델 생성
- 글로벌 모델 수신 후 각 클라이언트가 모델 매개변수 업데이트
- 로컬 최적 모델은 FL 서버와 공유됨
- Global Aggregation
- 참가자로부터 로컬 모델을 받은 후, FL 서버가 집계 수행 및 업데이트된 글로벌 모델 생성
- 최신 글로벌 모델은 다시 모든 새 참가자와 공유
첫 번째 단계에서 중앙 서버는 훈련 작업과 글로벌 모델링을 시작한다. 중앙 서버는 작업 요구사항과 대상 응용 프로그램을 결정하고, 글로벌 모델을 초기화하여 선택된 로컬 클라이언트인 참가자들에게 브로드캐스트한다.
두 번째 단계에서는 로컬 모델 업데이트가 이루어진다. 각 참가자는 자신의 로컬 데이터를 활용하여 모델을 생성한다. 글로벌 모델을 수신한 후, 각 클라이언트는 로컬 손실 함수를 최소화하는 방향으로 모델 매개변수를 업데이트한다. 이후 로컬에서 최적화된 모델들은 FL 서버와 공유된다.
마지막 세 번째 단계에서는 글로벌 집계가 수행된다. FL 서버는 참가자들로부터 로컬 모델들을 받아 집계를 수행하고, 업데이트된 글로벌 모델을 생성한다. 이후 최신의 글로벌 모델은 다시 모든 새로운 참가자들에게 공유된다. 두 번째 단계와 세 번째 단계는 중앙 서버가 글로벌 손실 함수를 최소화하여 수렴할 때까지 반복된다.
이를 수식으로 표현하면 아래와 같다.
\[min_{w}f(w)=\sum_{k=1}^{N}P_{k}F_{k}(w)\]여기서 $N$은 사용 가능한 장치의 총 수, $P_k$는 각 장치 $k$의 상대적 영향을 나타내며, $F_{k}(w)$는 $k$번째 장치의 매개변수 $w$에 대한 샘플 입력의 예상 예측 손실이다.
Taxonomy of FL-based Systems
FL은 데이터 분포에 따라 세 방식으로 분류할 수 있다.
- Horizontal FL (sample-based)
- 같은 feature 공간을 공유하는 다른 데이터 샘플
- 예: 다음 단어 예측, 깨우기 단어 감지, 추천 시스템
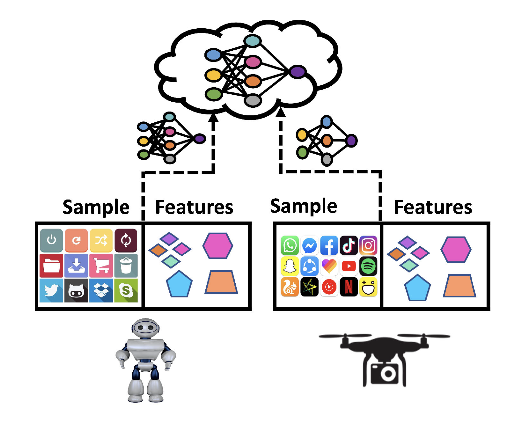 Horizontal FL scenario
Horizontal FL scenario
- Vertical FL (feature-based)
- 같은 샘플 ID를 공유하는 다른 샘플 공간
- 예: SecureBoost, FedBCD
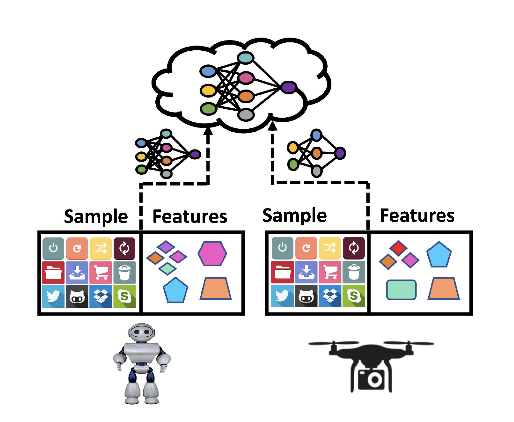 Vertical FL scenario
Vertical FL scenario
- Federated Transfer Learning (FTL)
- 데이터 샘플과 feature 공간 모두에서의 수평 및 수직 분할의 조합
- 예: COVID-19 백신 연구, 다른 국가의 다국적 기업
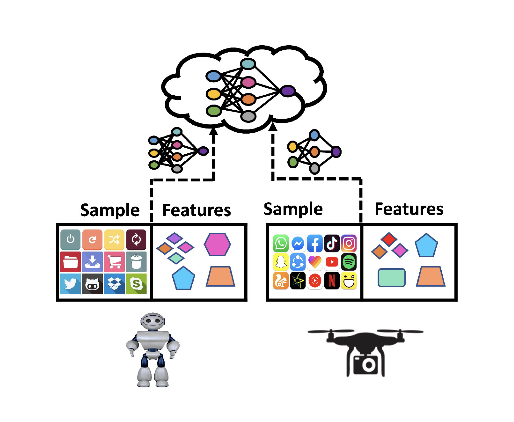 FTL scenario
FTL scenario
수평적 FL은 같은 feature 공간에서 다양한 데이터 샘플을 다룬다. 반면 수직적 FL은 같은 샘플 ID를 공유하지만 다른 샘플 공간을 가진다. 마지막으로, FTL은 데이터 샘플과 feature 공간의 수평 및 수직 분할을 모두 포함한 방식이다.
FL의 규모에 따라서는 두 가지로 분류할 수 있다.
- Cross-Device
- 클라이언트의 수가 많지만 각 클라이언트의 데이터 크기가 제한됨
- 예: Google의 지보드
- Cross-Silo
- 클라이언트 수는 상대적으로 적지만 많은 양의 데이터 보유
- 예: Amazon의 제품 추천
Cross-Device FL에서는 클라이언트의 수가 많지만 각 클라이언트의 크기는 제한된다. 예를 들어, 스마트폰이나 IoT 장치가 수백만 또는 수십억 대의 클라이언트로 고려될 수 있다. 최근에 Google에서는 사용자의 장치에서 모델을 훈련하여 서버에서 모델 정보를 집계하는 FL 기반 키보드인 지보드를 제안했다.
반면에 Cross-Silo FL에서는 클라이언트의 수가 상대적으로 적지만, 많은 양의 데이터를 보유하고 있다. 대표적으로 Amazon은 수백 개의 데이터 센터에서 수집된 데이터를 사용하여 모델을 훈련하여 제품을 추천한다.
실제로 FL을 적용하려면 클라이언트들이 훈련 단계에 참여하도록 하는 것이 필요하다. 이는 규제나 인센티브 메커니즘을 통해 이루어질 수 있다. 예를 들어 지보드는 사용자에게 데이터를 제공하도록 강요할 수는 없지만, 데이터를 업로드하는 사용자에게는 개인화된 키보드 기능을 제공한다. 이러한 인센티브는 사용자가 정보를 고유하거나 장치에서 학습을 수행하도록 독려한다.
Main Research Directions
위의 분류에 따라, 이 서베이의 저자가 기존의 FL 문헌들을 비교한 표이다. 여기서 DT는 decision tree, LM은 linear model, DP는 differential privacy, 그리고 CM은 cryptographic method를 의미한다.
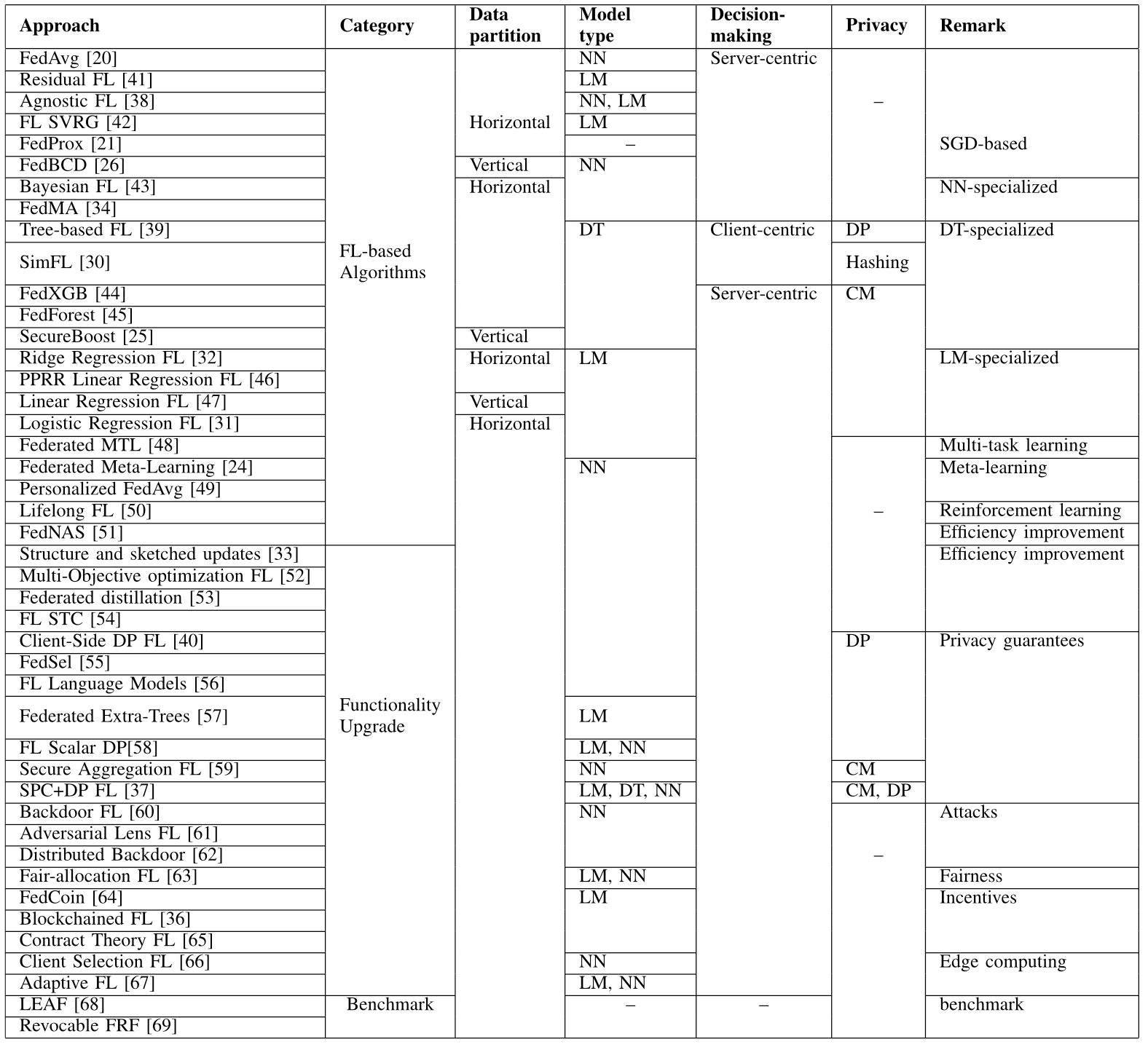 Comparing the existing FL literature
Comparing the existing FL literature
이전 연구들은 두 가지 주요 카테고리로 분류되는데, 크게 FL 알고리즘과 feature integration에 따라 분류할 수 있다. 예를 들어 federated averaging과 블록체인 FL 같은 것들이 있다. 각 연구는 또한 데이터 파티션 체계에 따라 수직과 수평으로 분류할 수 있다. 모델 유형에 따라서는 신경망, 선형 모델, 의사결정트리로 크게 나눌 수 있고, 일부 경우에서는 제안하는 접근법에 따라 더 확장된 ML을 사용하기도 한다.
그리고 요약하면, 서버 중심 설계를 기반으로 하는 접근법이 대부분을 차지하고 있다. 그러나 특히 cross-silo FL에서 이러한 서버 중심 의사 결정 아키텍처는 신뢰 문제에 대해서 논의되고 있다. Cross-silo FL 환겨을 처리하기 위한 방법들 중 주요한 것은 중앙 서버를 대체하고 각 클라이언트가 모델 파라미터를 공유하는 것이다. 이런 전략들은 서버 중심 접근법에 비하면 신뢰 문제를 해결하지만 한편으로는 연산 비용과 통신의 오버헤드를 증가시키는 trade-off가 있다.
FL Algorithms
FedAvg
Federated Averaging (FedAvg)는 중아 서벌르 통해 트레이닝한다. 이 서버는 공유된 글로벌 모델을 전파하고, 각 클라이언트는 SGD를 사용하여 로컬에서 최적화를 수행한다.

FedProx
FedProx는 FL 환경에서 클라이언트가 시스템 이질성의 부정적인 영향을 처리할 수 있는 비균일한 양의 작업을 수행해야 하는 상황을 고려하여 설계되었다. 근접 항을 추가함으로써 로컬 문제 내에서 클라이언트의 로컬 업데이트를 제한하여 통계적 이질성(heterogeneous) 문제를 해결하고, 다양한 양의 클라이언트에서 안전하게 작업할 수 있도록 한다.

q-FedAvg
q-FedAvg는 기존의 FedAvg 알고리즘에서 수렴 속도를 가속화하는 반면에 클라이언트 리소스를 공정하게 할당하지 못하는 문제점을 해결하기 위해 제안되었다. 리소스가 제한된 장치를 고려할 때, 클라이언트의 기여도에 따라 fairness를 부여하는 것이 중요하다. 이를 위해, FL의 objective function은 주어진 cost function과 fairness의 양에 따라 다음과 같이 정의된다.
\[min_{w}f_{q}(w)=\sum_{k=1}^{m}\frac{p_{k}}{q+1}F_{k}^{q+1}(w)\]
Distributed Learning
FL 프로세스에서 중앙 서버는 다수의 클라이언트들의 기여를 통해 학습 과정을 관리한다. 그러나 이러한 방식은 single point or failure의 취약점을 가지고 있어서 모든 부문에서 적용하기가 어렵다. 특히 일부 클라이언트들이 전체 FL 환경의 프로세스들을 지연시킬 수 있다.
이러한 문제를 해결하기 위해 fully distributed and decentralized learning과 같은 FL의 개념이 도입되었다. 이는 중앙 서버의 필요성을 제거하고 클라이언트들 간의 피어 투 피어 통신을 활용하여 학습을 진행하는 방식이다. 이러한 접근법을 통해, 모든 클라이언트가 각각의 로컬 모델을 통해 글로벌 솔루션에 도달하도록 설계할 수 있다. 특히 클라이언트들은 자신의 디바이스에서 학습한 다음 피어들로부터 학습하여 로컬 모델을 수렴시킬 수 있다.
또한 최근에는 decentralized SGD가 대규모 시스템의 확장성과 네트워크 장치의 분산을 위해 사용되고 있다. 하지만 분산된 환경에서도 하이퍼파라미터를 조정하거나, 알고리즘을 선택하거나, 시스템 실패를 해결하기 위해 중앙 권한이 필요할 수 있다. 이를 위해 클라이언트 간에 신뢰를 보장하는 프로세스가 필요하다.
Distributed and Federated Optimization
Distributed and federated optimization은 데이터 처리와 학습 효율성을 높이는 방향으로 발전해왔다. 초기에는 순차 알고리즘의 분산 버전이 주를 이루었는데, 이는 통신 측면에서 비효율적이었다. 이 비효율을 해결하기 위해 다수의 로컬 계산을 수행한 다음 통신 라운드를 통해 진행하는 방법이 제안되었다. DANE, CoCoA, 그리고 DiSCO와 같은 기술들이 이런 distributed optimization 기법의 예시로 들 수 있다.
이후 federated optimization이 도입되어 사용자의 데이터 보안성을 강화하는 데 기여했다. 이는 사용자가 데이터를 비공개로 유지하면서 계산 능력을 제공하는 방식으로, 데이터 포인트의 크기는 작지만 장치의 수는 많고 각기 다른 데이터 패턴을 가지고 있다.
Desirable Properties for Distributed Optimization
Distributed optimization을 위한 알고리즘을 설계할 때에는 고려해야 하는 몇 가지 중요한 특성들이 있다.
- 안정성(stability): 알고리즘이 최적의 솔루션으로 초기화되면 그 상태를 이쥬
- 효율성(efficiency): 단일 노드가 모든 데이터를 보유하면 O(1) 통신 라운드에서 수렴
- 분해가능성(decomposition): 모든 기능이 단일 노드에 있으면 문제를 분해하고 O(1) 통신 라운드에서 수렴
- 일관성(uniformity): 각 노드가 동일한 데이터셋을 가지면 O(1) 통신 라운드에서 수렴
Learning on Resource-constrained Devices
실제 IoT 환경에서는 제약된 리소스를 가지는 경우들을 고려해야 한다. 여기서 엣지 장치는 계산 능력, 저장 용량, 전송 범위, 그리고 배터리 수명과 같은 자원이 제한된 엔터티로 정의할 수 있다. 이러한 장치는 자원을 추가로 통합할 수 없기 때문에, 유동적으로 자원을 증가시키거나 감소시킬 수 없다. 때문에 대량의 데이터셋으로 이러한 엣지 장치를 훈련하는 것은 현실적으로 어려울 수 있다.
Communication Overhead
리소스 제약이 있는 IoT 노드를 FL 환경에서 고려할 때 마주칠 수 있는 주요 도전 과제 중 하나는 통신 오버헤드다. 서버와 클라이언트 간의 통신이 반복적이고 최적화되지 않았을 때 통신 비용이 주요 문제로 작용한다. 특히 리소스가 제한된 클라이언트는 큰 모델을 처리하는 데 어려움을 겪을 수 있다. 그러므로 클라이언트 모델을 압축하여 훈련 중에 추가 리소스를 낭비하지 않도록 해야 한다.
Heterogeneous Hardware
또한 FL 환경에서 다양한 제품 세대의 장치들이 함께 동작하면서 하드웨어의 heterogeneous가 나타날 수 있다. 이 때 네트워크를 구성하는 디바이스들은 계산 능력, 메모리 크기, 그리고 배터리 수명 등에서 차이를 보인다. 따라서 FL은 이기종 하드웨어 구성을 인식하고, 시스템 요구 사항에 맞는 클라이언트를 선택하여 훈련을 최적화해야한다.
Limited Memory and Energy Budget
제한된 메모리와 에너지 버짓도 주요한 챌린지다. 이기종 FL 클라이언트 간에는 메모리 사용량과 에너지 버짓에 큰 차이가 있다. 일부 클라이언트는 매우 제한된 메모리 크기를 가지고 있을 수 있고, 훈련 과정에서 시스템 요구사항을 충족시키기 위한 에너지가 부족할 수 있다. 이러한 문제로 인해 오버플로 상황이 발생할 수 있기 때문에 데이터 집계와 같이 제한된 크기의 데이터만 저장하는 관리 조치를 취할 수 있다.
Scheduling
현재 federated optimization 기술은 크게 동기와 비동기 훈련으로 분류된다. 동기 통신 방식에서는 모든 훈련 라운드에서 클라이언트의 일부가 작업을 수행하도록 트리거되는 반면, 비동기 훈련은 통신 지연이 클 때 더 빠르게 수렴될 수 있다. FL 프로세스에서는 참가자의 훈련 단계를 설정하는 스케줄링이 중요한데, 특히 서버와의 빈번한 상호 작용이 더 많은 리소스를 소모할 때 그렇다. 최적화된 스케줄링은 앞서 언급한 에너지 소비나 통신 오버헤드 측면에서도 도움이 된다.
Fairness in Federated Learning
FL 과정에서의 fairness는 클라이언트 리소스를 공정하게 분배하는 것을 의미한다. 각 사용자가 받는 서비스가 공정하기 위해, 공정한 리소스 할당과 정확한 분배가 필요하다. 리소스 할당 최적화와 인센티브 메커니즘에 대해 최근 연구가 이루어지고 있다.
Scalability of Federated Learning
확장성의 측면에서는 무선 통신과 사용자 선택의 최적화와 FL 손실 함수의 최소화를 목표로 하는 방법들이 제안되었다.
Privacy Issues
FL에서 개인정보보호 또한 주요 이슈이다. 훈련 과정에서 모델 업데이트를 공유하며 민감정보가 유출될 위험이 있다. 이를 해결하기 위한 방법들이 몇 가지 제안되었지만, 리소스가 제한된 장치에서 실행되는 것을 고려할 때 새로운 정보보호방법이 필요하다는 시사점이 있다.
Potential Solutions
앞서 말한 내용들은 현재의 FL 기술들이 리소스가 제약된 디바이스 환경에서 가지는 특징과 시사점들이다. 이 글의 마지막으로 잠재적인 솔루션들을 서술한다.
먼저 통신 오버헤드를 줄이는 것이다. 여기에는 분산 훈련이나 모델 압축과 중요도 기반 업데이트와 같은 방법들이 있다. 특히 통신 라운드를 줄이기 위해 클라이언트 데이터셋 사이에 중복성을 주입하는 방법이 있다. 하지만 클라이언트의 제한된 리소스를 다루기 위해서는 통신 비용과 리소스 활용 사이의 균형을 맞추는 리소스 최적화 알고리즘이 필요하다.
다음은 비동기 FL에서의 수렴을 보장하는 것이다. 대부분의 FL 접근법은 동기식 통신에 기반하고 있다. 이 방법은 모든 참가자가 충분한 리소스를 가지고 있다고 가정하기 때문에, 결과적으로 전체 정확도에 큰 영향을 주지 않는 느린 참가자도 모델이 수렴하게 된다. 반면 비동기 연합 학습에서는 서버가 모델을 수시날 때마다 집계를 수행하므로 stragler의 영향을 줄이고 시스템 내에서 확장성을 제공할 수 있다. 그러나 비동기 FL은 수렴을 보장할 수는 없다. 따라서 리소스가 제한된 클라이언트의 비동기 FL 통신에서 수렴을 보장하는 방법을 개발하는 것은 새로운 연구 방향이 될 수 있다.
참가자를 드롭하는 솔루션도 있다. 실제 IoT 환경에서는 네트워크 연결의 문제 때문에 참가자가 언제든지 네트워크를 벗어날 수 있다. 많은 FL 논문에서 모든 참가자가 연결을 유지한다고 가정하지만, 실제 환경에서는 그렇지 않다. 이 문제를 해결하기 위한 방법 중 하나로는 참가자의 리소스 사용을 모니터링하고 그에 따라 훈련을 조절하는 것이 있다.
마지막으로 개인정보보호에 관하여, 기존의 FL 접근 방식은 암호화 프로토콜을 사용하여 데이터의 개인 정보를 보호하려고 시도했지만, 이러한 방법은 통신 비용이 많이 든다. 그래서 리소스가 제한된 IoT 환경에서는 적용하기 어렵다. 이 문제를 해결하기 위해 블록체인과 같은 기술을 도입하는 연구도 진행되고 있으며, 향후 방향이 될 수 있다.